保留建模:原理、优势和需要避免的潜在陷阱
2025-01-02 12:35:28, ACD/Labs 阎作伟 Advanced Chemistry Development, Inc. (ACD/Labs)
保留建模
原理、优势和需要避免的潜在陷阱
演讲 / Dr. Jennifer Field, 岛津英国公司
翻译 / 阎作伟,ACDLabs

大家早上好,感谢ACD LABS邀请我今天发言。今天我将讨论保留模型的原理、优势以及需要避免的潜在陷阱,以及这如何帮助忙碌的科学家开发出他们一开始就有信心的方法。我们将讨论模型如何融入您的工作流程,以及为什么您会从执行保留模型中受益。

接下来,我们将讨论模型背后的原理,这些原理基于经验关系。然后,我们将研究一些实用的技巧和窍门,以充分利用您的模型,然后了解在模型中可能会导致问题的地方,这些问题是我们需要避免的。


方法开发是大多数实验室中执行的最关键的活动之一。通常,它可以采用一次一个因素的方法进行,这不利于智能工作和简化流程。它消耗大量资源,包括资金、溶剂、样品和科学家的时间。一次一个因素的方法着眼于一个变量,并在转向下一个参数之前确定该变量的最佳条件。这种方法的问题在于它不能建立可交互的关系,并且由于缺乏信息,最适合的工作空间常常会被错过。
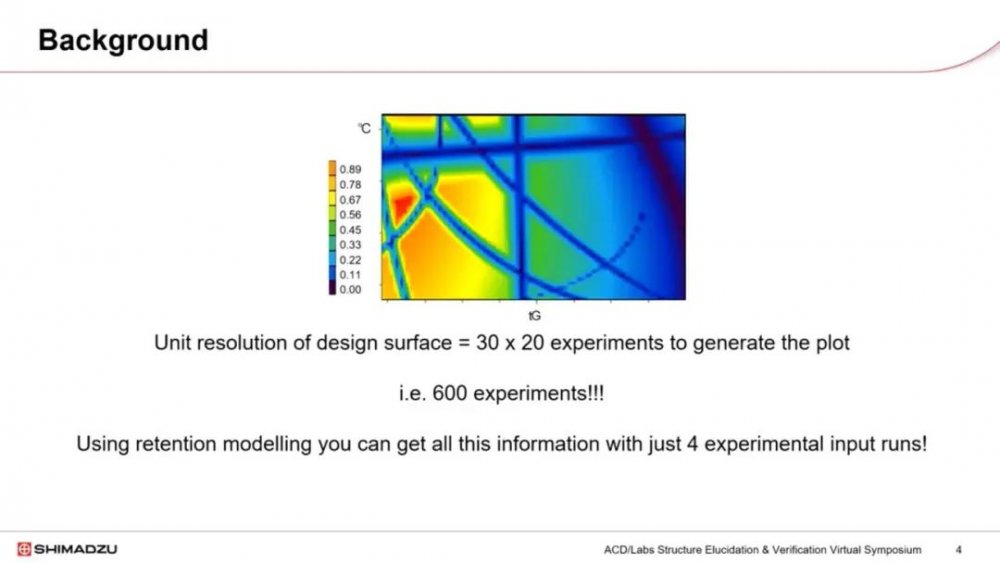
与一次一个因素的方法不同,保留模型允许我们基于色谱数学关系,用最少的实验数据创建一个设计空间。在这个图例中,这个设计空间需要进行30×20次实验来生成一个类似的热图,这意味着需要进行600次实验。像ACD Labs的LC-Simulator这样的软件利用众所周知的色谱和数学关系,将方法开发简化为只需要4次输入实验,这更容易执行。
那么保留模型如何融入您的分析工作流程呢?要开始整个过程,我们得有个实验设计阶段,在这个阶段我们需要决定分离的目标。这包括基于常规运行的样品数量或所需的最小分离度的任何时间限制。这也是一个探究物理化学性质的机会,比如在特定pH值下的logP或logD以及化合物和杂质的pKa。这可以使用ACD Labs的Percepta软件轻松确定。这些信息将为方法筛选阶段的决策提供依据,这将使我们能够确定合适的有机改性剂、pH值和色谱柱组合。
筛选使用统一的梯度时间和温度进行。然后将最有潜力的条件带入方法优化阶段,在这个阶段使用LC-SIMULATOR进行计算机模拟以优化分离。
最终的方法是基于最佳折衷选择的。然后可以对模型进行稳健性研究,软件可以预测各种操作参数(包括流速、流动相组成和滞留体积)中的系统误差的保留情况,然后遵循监管机构的要求进行方法验证。在不同用户、不同仪器和不同实验室之间转移方法,以确保方法完全可靠,最终该方法可以发布用于常规使用。
保留模型有几个好处。在这里,我将强调主要的好处。首先,通过进行建模所需的实验,我们对化合物的分离机制有了更深入的了解。我们拥有的信息越多,就越能理解这些分析物在色谱柱内发生的情况。由此,我们还获得了高度优化的操作,这是由于我们以系统的方式进行操作,考虑了一系列参数。我们显著简化了方法开发过程,一次一个因素的方法或者更糟糕的随机改变变量的随机方法,不允许我们建立变量间的关系。我们可能最终会花费大量时间追求一种我们永远无法完全满意的分离。通过构建模型,我们显然会节省大量时间、溶剂和样品。最近一直在大力推动提高可持续性并采用更环保的方法。实现这一目标的一个好方法是使用计算机模拟建模。最后,我们可以通过查看关键色谱峰对之间的分离度图来选择最稳健的工作区域。这使我们能够确定方法中的细微变化(如流速、温度或滞留体积的微小偏差)如何影响分离。如果方法稳健性损失太大,我们可能会决策放弃使用特定的空间。

ACD LABS 的 LC-SIMULATOR 中有许多模型,这些模型研究pH值、溶剂比例、盐浓度或上述因素的组合以及在不同模式下(如反相、正相、螺旋蛋白)的影响。最终用户选择最适合他们正在研究的条件的模型。

在这里我们将更详细地研究最常见的参数组合,即梯度和温度两因素组合。
此方面有大量文献可供您查阅,这些文献完美地描述了保留与有机相百分比或温度之间的关系,我鼓励您深入研究。我将简要描述它们在小分子反相色谱中的情况,有机相百分比与分析物的logk有线性关系,其中保留随着流动相中有机相比例的变化而变化。这被称为斯奈德线性溶剂强度模型。

每个分析物的斜率是都会不同的。然而在同系物系列中,每个分析物的斜率是相近的,因此,改变有机相将不是改变同系物选择性的合适参数。而对于具有不同物理化学性质的化合物,有机相百分比对每个物质的影响是不同的,这就可以产生不同的选择性,这是等度和梯度建模的基础。可通过仅进行两次实验,可以在每个点之间绘制一条线,并有望确定一个有机相组成百分比,该百分比将分离所有化合物。

然而,当我们有生物分子时,情况有点不同。生物分子对有机组成的微小变化非常敏感,这就是为什么它们通常采用长而浅的梯度方法。其构象高度受有机含量的影响,因此,需要一个多项式方程来描述这种关系。

对于温度,可以使用范特霍夫方程采用相同的方法,其中两个实验点形成线性关系,然后可以突出分离区域。观察到的差异是由于每个单独化合物的焓和熵。对于生物分子,我们需要一个不同的数学关系,该关系使用多项式方程,原因是当我们增加温度保留时观察到二级结构构象变化。
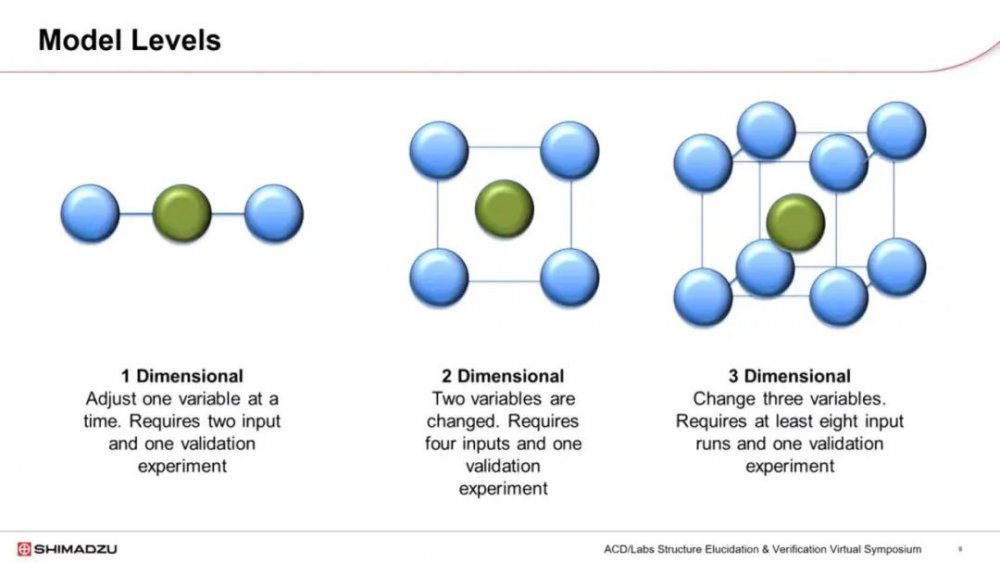
建模软件可以根据所研究的变量数量有不同的级别供我们研究。让我们考虑小分子保留建模。第一级是一维模型,它考虑单个参数。这种情况需要至少两次输入运行和一次验证运行,验证运行位于两个极端之间的中间位置。下一级是二维模型,这是迄今为止最常见的模型,两个变量被改变。这会产生四个实验点,这些实验点用作模型的输入,并且在正方形的正中间有一次验证运行。最后一级是三维模型,它改变三个变量,并在这个立方体中进行说明。在设计空间的角落有八个实验数据用于构建模型,还有一次验证运行。在本演示文稿的后续部分,我们将研究二维模型,因为它是最广泛使用的方法。

我们希望获得良好的数据来创建一个良好的模型。因此,在开始任何开发之前,我们应该遵循以下几点。了解分离的目的,并知道什么时候足够了。我们可能会花费宝贵的时间和资源试图找到最完美的方法,但相反,我们应该定义我们的标准,然后在满足标准时停止。我们需要查看感兴趣的分析物的物理化学性质,以便找到最可能的流动相和固定相候选物,确保我们的pH值至少离主要分析物的pKa两个pH单位,这也将提高我们分离的稳健性。要让所有分析物完全质子化或去质子化难度太大,所以在这种情况下要做出最佳折衷。从分析物的物理化学性质中,我们可以为筛选过程做出合理的选择,并选择最有可能分离大多数化合物的选项,同时确保我们不会对化合物造成任何降解。使用一根好的色谱柱很重要。我的意思是,一根我们知道性能良好的色谱柱。理想情况下,这应该是一根新柱子,但这并不总是可能的。所以,在那种情况下,使用一根有已知历史的柱子,它没有受到损害并且效率良好。我们也应该理想地在同一根柱子中使用同一批流动相,以相同的顺序运行所有实验,以确保我们数据的完整性。如果由于某种原因这不可能,那么应该在不同条件之间重复一次运行,以确保数据是可重复的,以便可以用作模型的输入。另一个好的做法是运行一个验证数据点,这在本演示文稿中已经描述过。这个中心点可以用于交叉检查模型的准确性。如果验证运行良好,那么我们可以继续花时间研究解决我们感兴趣的化合物的潜在条件。接下来,确保仪器运行良好。如果机器泵送不准确或者流速不正确,那么我们将无法创建一个准确的模型。如果化合物在梯度的线性部分洗脱,模型的准确性会提高。如果峰在梯度顶部的等度保持部分洗脱,准确性会降低。因此,根据色谱柱格式选择合适的条件以获得3到9的平均k值很重要。最后,在收集数据之前,确保色谱柱在每个色谱条件下完全平衡,并且在梯度运行后的冲洗中确保有足够的柱体积以产生有效的结果。这通常大约是10个柱体积。但请记住,您的图形模型的好坏取决于您的输入数据。所以,如果您不采取这些初步预防措施,您最终可能会得到一个糟糕的模型,做出糟糕的预测。

构建模型首先需要实验数据。所以,对于梯度温度二维模型,需要将四次实验数据输入模型。我们需要知道色谱柱死体积和仪器滞留体积。这些值定义不准确会导致不准确的预测,我将在后面更详细地讨论这一点。我们还需要知道分离的流速。一些可选信息包括色谱柱尺寸、峰宽、峰面积和峰拖尾,这些将有助于提高分离度预测的准确性。

所以这里有一个典型的例子,展示了一旦输入色谱数据后得到的结果。在顶部我们有分离度图,它在x轴上显示梯度时间,在y轴上显示温度。温暖的红色表示更高的分离度,而蓝色区域表示相关性。我们显然希望在高色温的区域工作。LC-Simulator的好处在于,无论您在分离度图中点击哪里,都可以看到相应的色谱图,如图底部所示。它在色谱图中以红色突出显示关键峰,以便轻松显示分离中分离度最低的位置。

文献中有几种方法来确定滞留体积。滞留体积是在溶质相遇点和色谱柱头之间测量的。我们需要知道滞留体积,因为每个系统的流动相组成变化会不同,这意味着它在两台液相色谱仪(如超高效液相色谱仪和传统高效液相色谱仪)之间转移方法时起着关键作用。我们还可以在软件中调整滞留体积值,以最小化模型残差的差异。一旦测量过一次,除非流路发生重大变化,否则不需要再次测量。

柱外谱带展宽是衡量在色谱柱外发生的导致峰展宽的贡献的量度,这会使峰变宽。在高效液相色谱系统中,这种贡献相当小,但对于使用高效色谱柱的超高效液相色谱系统,影响变得显著。通过调整这个值,应该可以更准确地描述峰形。

死体积是未保留化合物的保留体积。我们可以近似死体积或通过实验推导它。有一些粗略的估计可以用来指导最终用户。第一种计算是对圆柱体的基本测量,而第二种计算考虑了颗粒的孔隙率。区分表面多孔颗粒和传统多孔颗粒很重要。然而,确定死体积的更好方法是通过实验,对于使用什么是最好的标记物,水和尿嘧啶是最常见的标记物。然而,在反相色谱中,我们确定该值受pH值和溶剂组成的高度影响。

这里有一个死体积与流动相中乙腈含量在不同pH值下的关系图。对于两种分析物,测量值确实会随着不同的有机组成而改变。然而,最大的问题是在不同的pH值下,两种标记物在pH 10.7时都有更大的偏差,但尿嘧啶的偏差更大。这是由于在pH 10.7时尿嘧啶和离子化的硅醇基团相斥,而水在高pH值时被迫更深入地渗透到硅胶表面,因此保留更多,因为尿素受pH值变化的影响更大,而水通常会给出一个清晰的负峰。为了明确测定,我建议使用水作为标记物。

幸运的是,模型可以准确地预测保留,死体积误差在正负20%以内,对于等度和梯度洗脱,模型误差都小于1%。
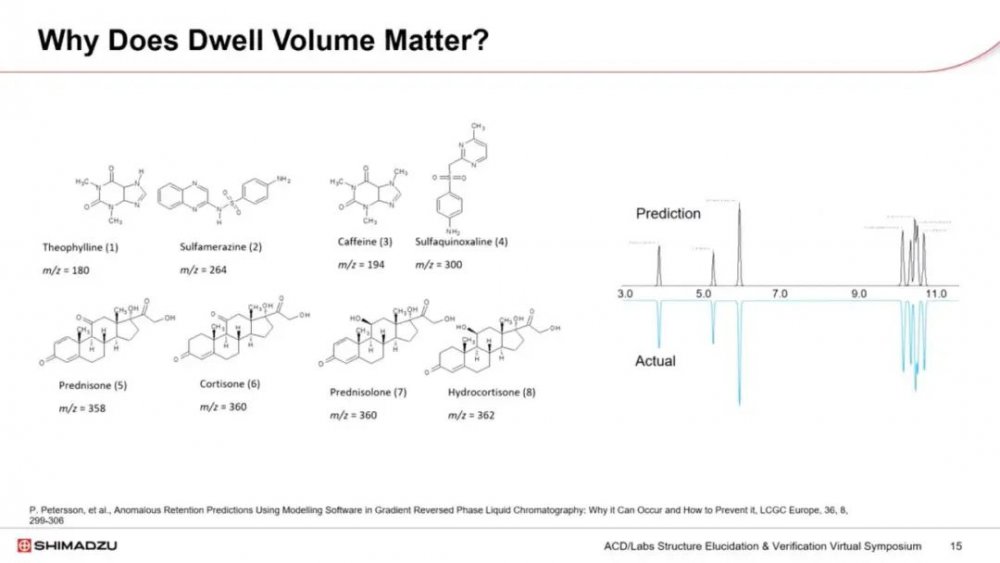
滞留体积会造成什么问题呢。我们评估了八种极性范围不同的化合物。梯度验证实验非常吻合。
然而,当我们使用模型追求最佳分离时,预测结果与实际实验不匹配。一些%B与logk实验很快表明,三种最极性的化合物保留比预测的略大。

本例使用了实验得出的滞留体积,但显然建议的值更大。为了减少残差,ACD Labs引入了一个滞留体积调整工具,可以将滞留体积从实验得出的值更改为建议的值,这可以显著提高模型的准确性,如图所示。所以,如果模型推荐的初始%B显著高于输入的初始%B,就会出现误差。为了克服这个问题,可以使用迭代方法确定滞留体积以减少残差误差,或者使用滞留体积调整工具以获得更好的指导。

那么当我们设计实验时,我们的模型能有多准确呢?我们设置四次输入运行,在我们的示意图中是蓝色圆圈。我们在设置中还包括一次验证运行,在示意图中是绿色圆圈。这是一个中心点,用于评估模型的有效性。
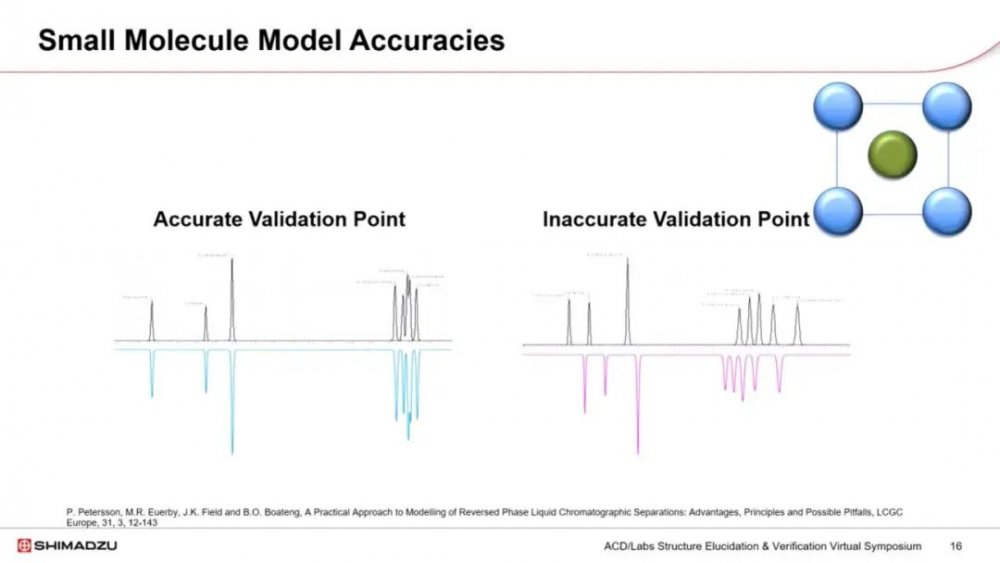
实验结果和预测之间的良好拟合会让我们对模型有信心。相关性差表明模型不适合目的,所以我们不应该继续使用它。如果我们使用这里突出显示的计算,我们可以计算保留时间的预测误差。小于2%通常被认为足够好,尽管我们可以从结果中看到百分比误差非常小,最大偏差为0.11,分离度值有点大。

然而,重要的是要批判性地评估数据。如果我们检查四氯喹啉酸和酮洛芬之间的分离度,误差为2%。然而,实际分离度为3.6,预测为3.53,显然在可接受的范围内。
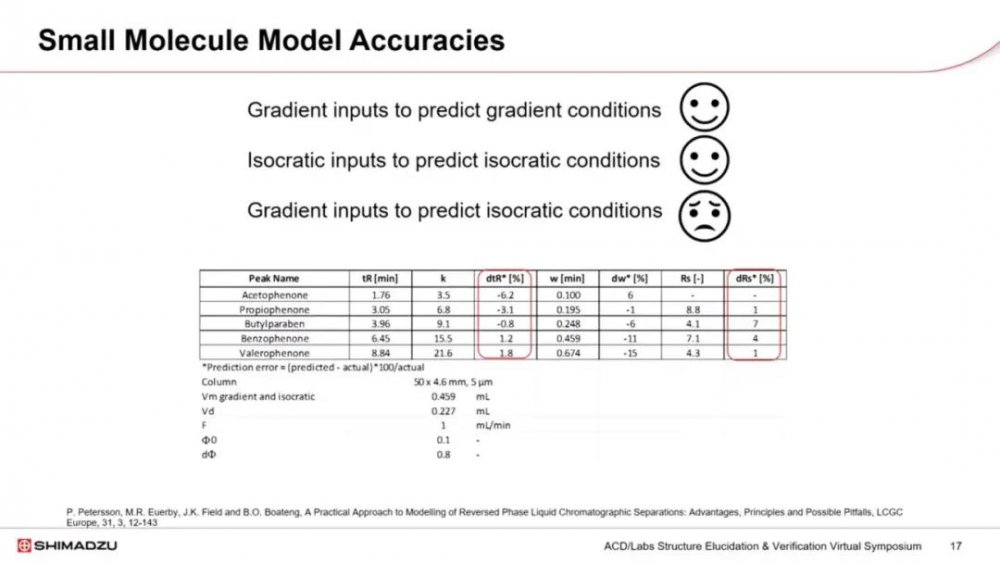
然而,有一点需要注意,如果我们使用梯度输入,我们可以非常准确地预测梯度条件。我们也可以从等度输入准确地预测等度条件。然而,如果我们尝试使用梯度输入但从中开发等度方法,就会出现问题。我们可以看到,对于保留时间分离度,我们观察到与此相关的更大误差。这对于早期洗脱物尤其成问题。分离度可能是由等度条件下的峰宽引起的,而在梯度条件下,峰宽通常是相同的。

生物分子是一类不断增长的化合物,在制药领域中用于靶向治疗,基于销售额的十大药品中有八种是生物分子。然而,用于预测生物分子的模型过去准确性相当差。但这是为什么呢?
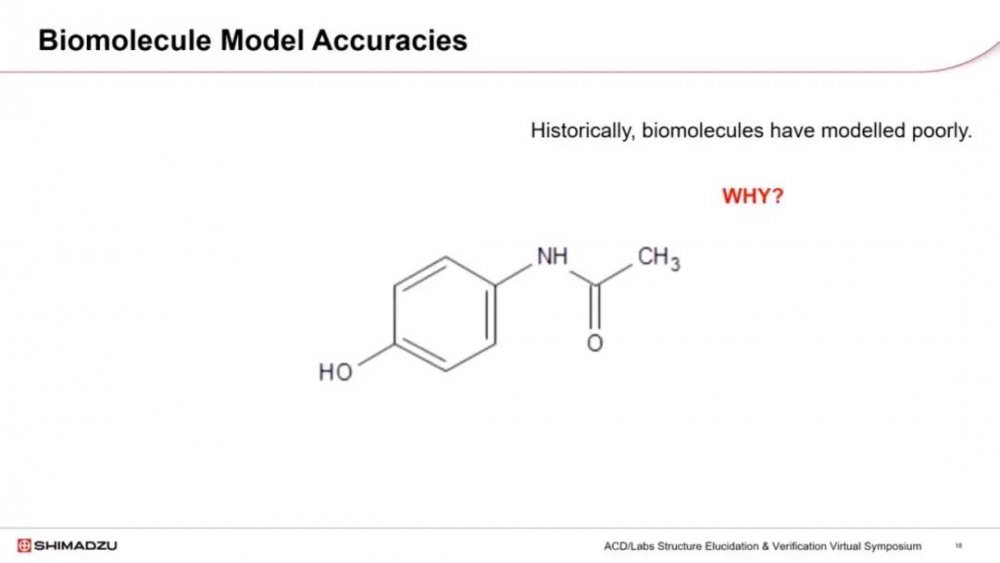
让我们考虑对乙酰氨基酚,一种分子量为151的小分子,可以使用传统关系很好地建模。然后让我们看看一种蛋白质,如碳酸酐酶,分子量约为30,000道尔顿。很明显可以看出它们的结构复杂性有很大差异。

如我之前所述,大分子的数学关系比基于范特霍夫或线性溶剂减法模型的典型小分子更复杂。如果我们看这个范特霍夫图,我们可以想象随着温度升高,蛋白质的构象会发生变化。然后我们有这个香蕉形曲线,其中蛋白质构象完全改变。因此,对于二维模型,我们需要更多的实验数据点来描述设计空间。与小分子的四次输入运行不同,对于生物分子,我们将进行3×3次实验运行和一次验证运行来正确描述。

为了解决这些结构问题,ACD Labs添加了一个模型,该模型使用二阶方程来更好地描述有机相百分比或温度与较大生物分子(如肽和蛋白质)之间的关系。在下面的例子中,我们可以看到一个肽和胰蛋白酶消化杂质的分离度图,方法开发基于红色区域中的最大分离度,右侧的预测分离用红色显示。我们可以从黑色轨迹中看到主峰和杂质都得到了很好的建模。重要的是要记住创建一种方法,能有效避免基质效应。

然而,有各种误差来源可能会给我们的模型带来问题。潜在建模的第一个陷阱来自我们的数据。如果我们有质量差的数据,我们必然会有一个质量差的模型。输入垃圾,输出垃圾。我们需要花时间获得高质量的数据,希望使用之前描述的一些提示和技巧。我们的下一个问题是峰归属。峰归属可能是保留建模最大的弱点。当我们使用互补技术(如DAD、质谱和峰面积)时,这项任务会更容易管理。有一些软件可以帮助进行峰归属。然而,它们都在处理同量异位素物种或具有相似色谱图的化合物时遇到困难。但是正在努力解决这个问题。峰形建模通常不如保留时间准确。然而,对于强度相等的峰来说是相当合理的。这有助于使分离度预测更准确。然而,对于经常在活性药物成分峰中看到的过载不对称峰,软件很难预测其峰形。下一个误差通常与打字错误或转录错误有关。当数据处理与建模软件没有连接时,就会发生这种情况。然而,如果数据使用ACD Labs的Spectrus Processor进行处理,它可以相当无缝地传输到LC-Simulator中,将这种风险降至最低,就像大多数软件一样。有大量的功能没有得到充分利用,这可以帮助最终用户。所以,我鼓励您与任何软件提供商交谈,尝试充分利用您的软件来帮助您的日常工作。最后,生成这些模型通常需要花费时间。然而,我们经常不与下游人员分享所有信息。所以,分享建模信息是有利的,例如,如果必要,我们可以根据模型重新开发方法。

所以,总之,我们需要良好的数据作为输入才能得到一个好的模型,有了差的数据,我们只会生成一个差的模型。我们需要花时间确定分离的目的,以指导开发过程并充分利用我们的模型。我们可以从潜在建模中获得大量信息,这可以促进产品的整个分析生命周期,从方法开发到方法稳健性研究,再到方法转移和常规使用。这些信息是从很少的输入实验中收集的,这使我们能够以更可持续和合理的方式工作。我们之前看到,生成二维模型所需的等效单个实验数量大约为600次实验。但是通过计算机模拟建模,我们可以将其减少到这四个可管理的实验。然而,我们需要花时间彻底检查我们的数据,以确保我们正确地跟踪峰,错误识别会影响我们模型的准确性。最后,只要我们选择最合适的数学关系,我们就可以为小型常规分子以及较大的生物分子获得准确的模型。

再次感谢ACD Labs给我今天发言的机会,并为岛津英国公司提供方法开发套件软件。感谢大家的聆听。如果有任何问题,我很乐意现在回答。
END
在色谱模拟沙龙第十九期中,ACD/Labs的阎作伟经理对该演讲内容进行了详细讲解,欢迎大家收看回放:

04-20
GLMY创想仪器丨亮相江苏东海高纯石英材料产业大会04-18
瑜伽裤有“毒”?Lululemon被曝添加“永久性化学品”:PFAS危害到底有多大?04-17
展会预告 | 安东帕邀您共赴 Chinaplas 202604-17
免费试用70天!安东帕傅里叶变换红外光谱仪助力药企生产04-17 Anton Paar China
精酿人必看 | 如何让啤酒新鲜度“破局”?三大福利,抓紧来领!04-17 Anton Paar China
邀请函 | 密度黏度联合用户培训会@上海04-17 安东帕中国
展会邀请,欢迎理论指导04-17 上海棱光技术
GLMY创想仪器丨于杭州聚焦再生生物油脂高质量检测04-17
脂质研究必看:2400+产品目录,四大难题一网打尽04-16
第35届化学年会圆满落幕,Sigma-Aldrich®赋能化学,共启化学探索之旅04-16
与时俱进,与药典接轨:一文看懂离子对试剂怎么选04-16 Merck
北京佰司特科技携手大连理工大学举办高速原子力显微镜与纳米生命科学研讨会04-16 北京佰司特科技
椰子水掺假?同位素质谱帮你看穿真相04-16 飞飞
纺织品PFAS风险升级,我们该如何看待“隐形污染物”?04-16 飞飞
食检人必看 | 2026年食品抽检新增项目与难点项目岛津应对合集04-16 岛津实验器材
抽检新增 | 功能饮料中双醋酚丁等19种化合物的测定04-16 岛津实验器材
热点方案 | GCMS法测定水产品中6种丁香酚类麻醉剂的残留量04-16 岛津实验器材
八十六载深耕·智领监测新篇 | 雷磁亮相2026上海环博会,解码十五五环境监测新趋势04-16
HC57系列pH电极在陶化工艺中的应用04-16 哈希公司