基于悟空云平台的蛋白质组和代谢组数据分析(九 统计分析.之.主成分分析)
2025-03-25 14:41:23, 诗盛 上海易算生物科技有限公司
本系列的基本逻辑路线:原始数据由来--->原始数据获取--->搜库获得表格数据--->表格数据分析(数据质量控制-->单元多元统计分析-->富集分析等等)。所以建议刚看的伙伴们从第一回看起。
后续所使用的分析工具主要是由本人亲手编写的“悟空云平台”,也不要忘了本平台的金牌赞助商---Omicsolution(http://www.omicsolution.com/),也请大家多多支持该司的业务。
欢迎大家加入我建立的QQ群:688728477~~在群里大家可以任意提问与解答相关的问题。也鼓励小伙伴们付费咨询群主,群主可以手把手教你玩数据~~
请大家关注转发,欢迎更多的小伙伴“入坑”,这个领域需要你的力量~
~





 ~
~往期回顾:
《基于悟空云平台的蛋白质组和代谢组数据分析(蛋白质组 一)》
《基于悟空云平台的蛋白质组和代谢组数据分析(二 原始数据获取)》
《基于悟空云平台的蛋白质组和代谢组数据分析(三 蛋白质组数据搜库)》
《基于悟空云平台的蛋白质组和代谢组数据分析(四 代谢组原始数据处理)》
《基于悟空云平台的蛋白质组和代谢组数据分析(五 数据预处理/前处理.之.数据筛选)》
《基于悟空云平台的蛋白质组和代谢组数据分析(六 数据预处理/前处理.之.数据质量控制)》
~~~~~~
书接上回,上回我们聊到了假设检验,从这些方法中我们可以得到一个常用的筛选差异表达物的指标---P值,并且本人也建议,当你的对象(蛋白质、代谢物或者基因等等)个数比较多时,这时候应该使用校正以后的P值。此外,我们也提到,在这个过程中,我们也可以直接得到两组样本的比值,即倍数变化(Fold Change,简称FC),这是我们用来筛选差异表达物常用的第二个指标。
那么接下来,我们接着聊多元统计分析中常用的主成分分析(Principal Component Analysis,简称PCA)。其原理我在这里就不做介绍了,网上资料实在是太多,感兴趣的话,也可以看下下面这篇文章,个人觉得讲的也是很不多的:

但我们需要知道的是,PCA是一种线性组合原始指标的无监督方法,也就是不会预先告诉模型类别标签的情况,模型在求解的时候也不会用到这个信息。在进行PCA求解的时候,核心是用到了奇异值分解(https://en.wikipedia.org/wiki/Singular_value_decomposition),比如在R语言中,我们常用的是prcomp函数,我们可以查看下其源代码:

如果暂时看不懂的话,没关系的,知道怎么去用就好,至于原理部分,可以后续慢慢去研究。
其用处也是我们常乐道的“降维”~~那么在我们蛋白质组、代谢组亦或基因组数据分析领域,其常用来画一个2维或者3维得分图,看下样本的分布情况,像这样:

其背后的逻辑就是,同一组处理下的每一个生物学重复中,蛋白质、代谢物亦或基因表达量应该相近,那么在这种得分图中,他们应该离的比较近,并且不同组之间相距应该比较远。这样的话,才说我们的实验数据结果相对比较好。比如一个控制组和给药组的数据,如果在这种图中,不同组的样本交叉混合在一起了,很有可能说明:
1. 实验过程人员操作不严谨?样本搞混淆了?
2. 加的药根本没有任何用?药品买的是假货?
3. 数据处理过程不恰当?
4. 数据处理方法没有选择合适?
5. ......
这些有可能的问题都值得我们反思一下。所以,这也是我们在做代谢组数据分析时,用Quality Control(QC)的样本,来评价数据质量(比如批次效应处理的情况)的一种形式:

那么在悟空云平台怎么做呢?
首先,还是用电脑打开官网:http://www.omicsolution.org/wu-kong-beta-linux/main/,在“功能圈”的“统计分析”模块中,找到“PCA分析”:

其次,打开对应的模块:

还是那样,如果你不导入你自己的数据,这里给出的就是示例数据,你的数据形式应该跟示例数据保持一致。现在假设我们导入自己的数据(前几回那个细胞的数据,应该都还记得吧~~):
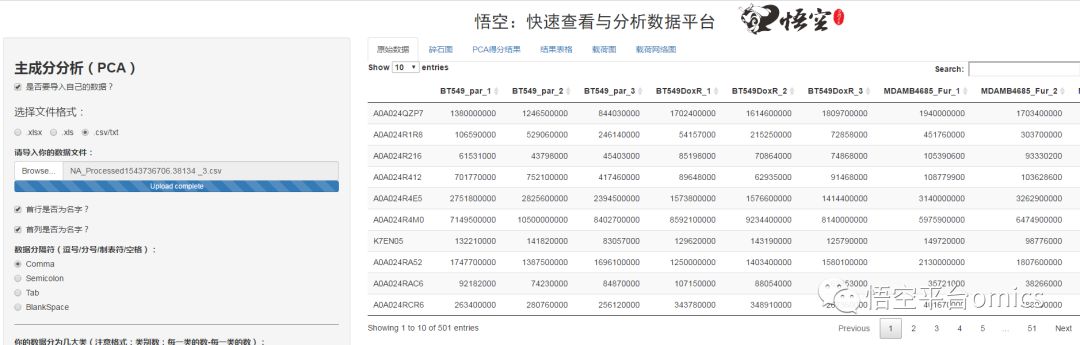
然后,我们就要根据我们这个数据情况来简单设置下参数了,前面说这个,这个数据是有4种细胞,也就是4组,每一组生物学重复3次。所以这里的参数设置应该如下:

再次强调一点:这里,我们的样本有4组,所以类别名称应该有4个,颜色应该也选中4个!
最后就是点击对应的结果按钮,结果就直接算出来:
1. 碎石图:
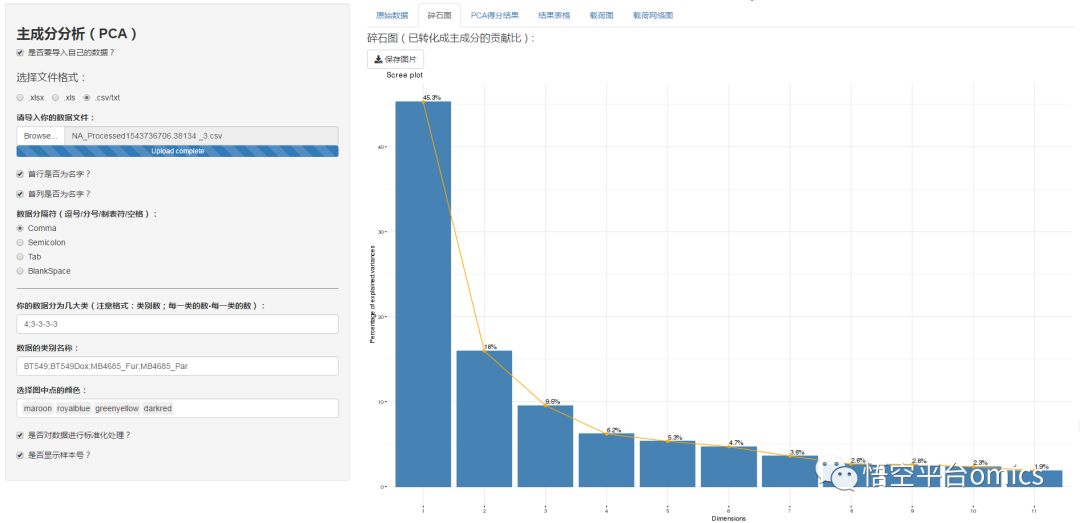
该图展示每一个主成分占比的分布情况。
2. 2维得分图:

这个就是我们经常在文献里面看到的图形形式。
3. 载荷结果和得分结果表格:

这里的载荷表格给出的是一种系数,反映的是每一个蛋白质与主成分的相关性,这也是画后面载荷图以及载荷网络图的数据来源。主成分得分结果就是每一个样本在每一个主成分中的得分值,前两列数值也就是用来画上面说的得分图。不过这里多说一句,二维得分图,我们经常看到的是用第一主成分和第二主成分的得分来画,但是不说一定就要用这两个,这个表中,任何2列都可以用来画那种得分图,或者3列来画3维图!
4. 载荷图:
这里需要注意的是,当导入的数据量比较大时,也就是行数太多,这里会给一个提示,说的是,在计算的过程中,计算比较耗时:
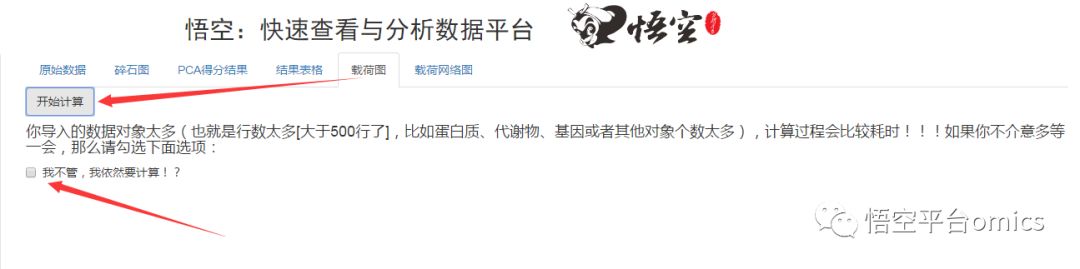
如果你不介意多等一会,那么就勾上下面的选项(导入的数据越多,需要计算的时间越长),比如数据比较多的时候,给出的图是这样的:

是的,你没有看错,就是这样一坨,其表达的意思就是越红表示该蛋白质对主成分的贡献(或者相关性)越大~~所以当数量比较大的时候,这种图的可读性几乎就没有了。不过还是看你个人喜好。
当数据量少一点时:

是不是就容易看一些!~
5. 载荷网络图:
这个跟载荷图表达的意思一样,就是另外一种表达形式而已,所以当数据量比较多的时候,也会给一个提示:

如果你不介意,最后算出来的结果大体像这样子:

可读性也不高,中间的每一个白点就表示一个主成分,外面一圈就是每一个蛋白质,越红色表示越正贡献(或者正相关),越蓝表示越负相关。
当数据量少一些时:

结果显示稍微清晰一些~~
~~~~~~
这就是做PCA分析常用的一些结果展现。当然,PCA的用处远不止我上面说的这些,基于PCA的方法(亦或是奇异值分解)延伸的其他的方法也不少。以后有机会咱们再聊其他的,至少现在这些基本的,常用的咱们要掌握好。
---------
PCA分析是一种无监督方法,不预先考虑类别标签。那么有没有预先就考虑类别标签的方法呢?!是有的,咱们下回继续聊。
预知后事如何,且听下回唠嗑~~
---------
让人人都方便分析自己的数据!本人致力于打造一款国内较为实用的数据分析云平台(http://www.omicsolution.org/wu-kong-beta-linux/main/),为广大国内有需求的小伙伴提供帮助,也感谢大家关注转发,以求帮助更多的人,谢谢
关注一下又不会怀孕,哈哈。。。
平台目前包含的工具(还在持续更新中...):



04-27 环亚生物
Blue Pippin全自动大片段DNA回收仪用于ONT纳米孔测序建库助力精准生殖医学检测研究04-27 环亚生物
文献速递|Blue Pippin全自动DNA脉冲场电泳回收仪用于单分子蛋白组学识别技术开发04-27 APGBio
Pippin 系列全自动DNA片段回收仪用于GUIDE-seq2测序——《Nature》 CRISPR–Cas9 PAM变体研究04-27
总投资2.71亿元!又一国家质检中心开工建设04-26
仪器租赁 | 赛默飞 离子色谱,月租金9590元起04-26
适配GB/T 4706.53,权威认证 | 气体腐蚀试验系统高效解决方案04-25
即将截止!一地方启动检验检测机构能力验证,无故不参加将被通报04-25
展会邀请 | 第八届全国食品风味化学与感官分析大会04-25
国产Biacore正式上市!04-24 Cytiva
看直播,领证书!植物抗逆研究前沿进展研讨会即将开始04-24 Cytiva
兰格CF系列分配型蠕动泵PC控制软件免费版发布!即日起,通过官网即可下载!04-24
仪器租赁助力糖类检测,成本更可控!04-24
重组成功!全国重点实验室名单,来了!04-24
一单一库外的检测活动还能开展吗?附检测资质能力项目库更新04-24 cici
从AI到天然淀粉,诺力昂如何解锁美妆新玩法?04-24 Nouryon诺力昂
Hanking液相色谱柱全系列重磅上新04-24 汉尧
双喜临门!东西分析荣获“售后服务十佳企业”,GC-MS 3250入选“国产好仪器”04-24
直击越南展会现场|东西分析携GC-4200与AA-7050硬核亮相,尽展中国智造实力04-24
深耕西北,共绘蓝图 | 2026北京东西分析新疆技术交流会圆满落幕!04-24