上镜率持续走高的桑基图,如何用多种方法绘制?(附代码)
2021-10-08 17:03:41, 多层组学定制服务 上海欧易生物医学科技有限公司
蛋白组学、代谢组学服务专家
一. 桑基图是干什么的
桑基图(Sankey diagram)本质上是一种流图(flow diagram),最早由爱尔兰人Matthew Henry Phineas Riall Sankey 提出的。早期是用于描述能量、人口或经济等的流动分布情况,故又称为桑基能量分流图或桑基能量平衡图。
近年来桑基图在各大期刊的上镜率在持续走高,比如2021的纯生物信息学文献:《Conserved pan-cancer microenvironment subtypes predict response to immunotherapy》,就有一个看起来超级复杂的桑基图,图例:(C) Sankey plot showing antigenicity and TMB (left) per TME subtype linked to mutation group (right) across TCGA patients at the pan-cancer level.
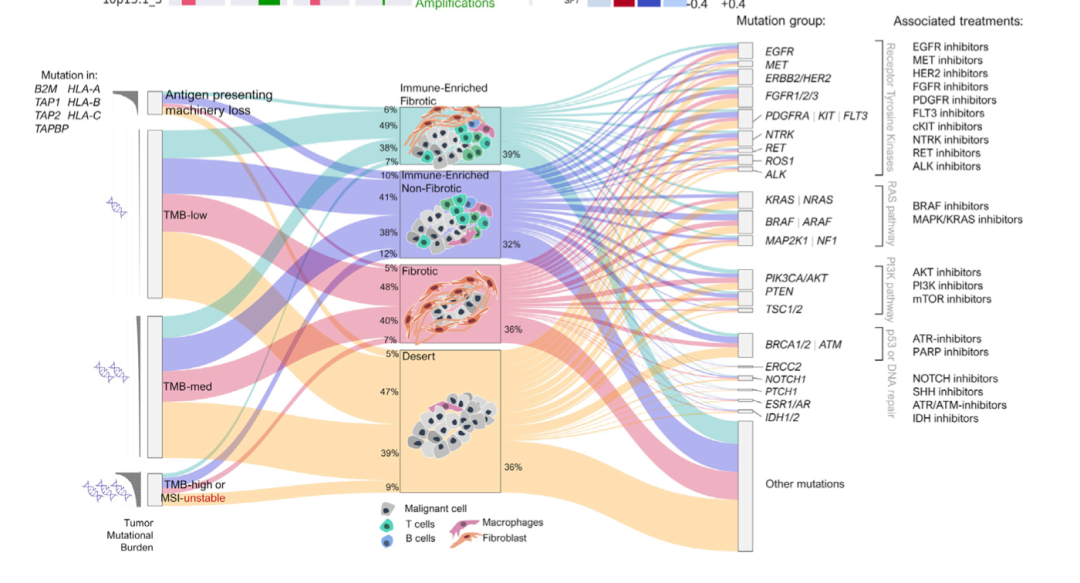
那么,什么样的数据适合桑基图呢。一句话,需要体现不同对象主体在不同属性上变化过程的数据,均可用桑基图。数据的形式类似这样(以Titanic数据集为例):
ClassSexAgeSurvivedn1stMaleChildNo02ndMaleChildNo03rdMaleChildNo35CrewMaleChildNo01stFemaleChildNo02ndFemaleChildNo0
数据拆解:这里每一行数据对应的是泰坦尼克号里的一个人(对象主体),每一列是这个人的所具有的某一属性(如Class是什么,Sex是什么等),而我们又正好需要展现不同人的不同属性的流向分布,这个时候桑基图就登场了。所以,桑基图呈现的是,横坐标是属性名,纵坐标是对象主体(对象数过多的话,画图不好看,往往用描述统计代替,常用的是频数),如:

二. 该如何实现
这里以上述的Titanic数据集为例,多种方式来实现。首先介绍alluvial包。
# 安装alluvial包# install.packages("alluvial")library(alluvial)library(dplyr)tit <- tibble::as_data_frame(Titanic)tit %>% head()|Class |Sex |Age |Survived | n||:-----|:------|:-----|:--------|--:||1st |Male |Child |No | 0||2nd |Male |Child |No | 0||3rd |Male |Child |No | 35||Crew |Male |Child |No | 0||1st |Female |Child |No | 0||2nd |Female |Child |No | 0|06-18 TESCAN中国
解决临床创新“卡脖子”难题,丹纳赫重磅推出医院创新转化解决方案!06-18
徕卡精准空间生物学解决方案 第三弹06-18 郑晓业、童昕
618 嗨购一起“徕” | 网上商城活动来袭!06-18 徕卡显微系统
【培训活动】显微镜成像高阶培训系列(一) 共聚焦多维度成像技术解决方案06-18 徕卡显微系统
【展会】第十五届中国医师协会骨科医师年会06-18 徕卡显微系统
【直播预告】第十届电子显微学网络会议06-18 徕卡显微系统
【案例研究】双视野光片显微镜,适用于类器官及胚胎06-18 徕卡显微系统
议程确定|第四届锂离子电池热测试主题研讨会06-18
文献解读|安徽理工大学马衍坤教授团队《煤炭学报》:震动载荷多次作用下烟煤孔裂隙结构演化特征试验研究06-18 纽迈分析
中国的新质生产力正在服务全球市场!GE医疗北京基地CT交付量达3.5万台/套06-17
兰格ACHEMA 2024展会回顾:探寻精密流体传输市场新机遇06-17
宝英科技推出VOCs治理设施精细化管理实施方案,助力重点行业企业绿色升级06-17 宝英科技
赛默飞X先锋“肽”势:多肽药物研发与创新研讨会06-17
一省检验检测行业营收突破160亿元!06-17
仪器租赁 | 沃特世 液质联用,月租金52000元起06-17
不同行业实验室“以旧换新”,涉及哪些仪器设备?06-17
目标!检验机构总营收超100亿!06-16
一张“A4纸”售价高达万元,这家第三方检测公司是怎么做到的?06-15
GLMY创想仪器丨参加东北地区铸造年会06-15 国产精密仪器厂家