Science重磅丨DNA编码化合物库(DELs)即将被取代!
2024-05-11 14:18:46, 助力药物研发的
DNA 编码化合物库 ( DNA encoded libraries, DELs ) 是一种与特定 DNA 序列共价连接的小分子化合物库,通过对结合化合物的 DNA 序列进行扩增和测序,可以有效地识别该化合物,从而进行快速而大规模的高通量筛选。
这种 DNA 修饰的优势在于通量高、合成成本低,且编码能力强,对于一段碱基长度为 10 的 DNA,能编码 410 种小分子。
但为了保证 DNA 标签的完整性,能采用的修饰方式有限。而这些 有限的修饰方式 以及 DNA 本身 都会影响小分子与蛋白的结合能力。
鉴于 编码化合物技术 在药物发现中的巨大潜力,当前急需一种信息载体更稳定、更多样化的互补平台来克服 DNA 编码的限制。
2023 年 3 月 2 日,来自美国麻省理工化学系的 Buchwald 和 Pentelute 研究团队在 Science 期刊发文 Abiotic peptides as carriers of information for the encoding of small-molecule library synthesis ,提出了 使用非生物肽作为编码小分子化合物库信息的载体,为下一代编码化合物库技术建立了一个起点,对药物发现和其生化性质的研究都具有广泛的意义。

原则上,只要能够实现有效的 编码 和 解码,任何具有两种以上不同单体的聚合物都可用于信息的存储。
多肽是另一种常见的生物聚合物,相较 DNA 有更强的 稳定性 和 编码能力(20 多种氨基酸),且可以通过 多肽固相合成 (solidphase peptide synthesis, SPPS) 技术 来完成编码,通过 纳米级液相色谱-串联质谱(nanoscale liquid chromatography–tandem mass spectrometry, nLC-MS/MS) 技术 被测序解码,因此其作为信息存储系统具有极大的潜力。
本研究将这些技术相结合,作为下一代 以多肽为编码载体的化合物库信息存储系统 ( peptide-encoded libraries, PELs ) 的基础。
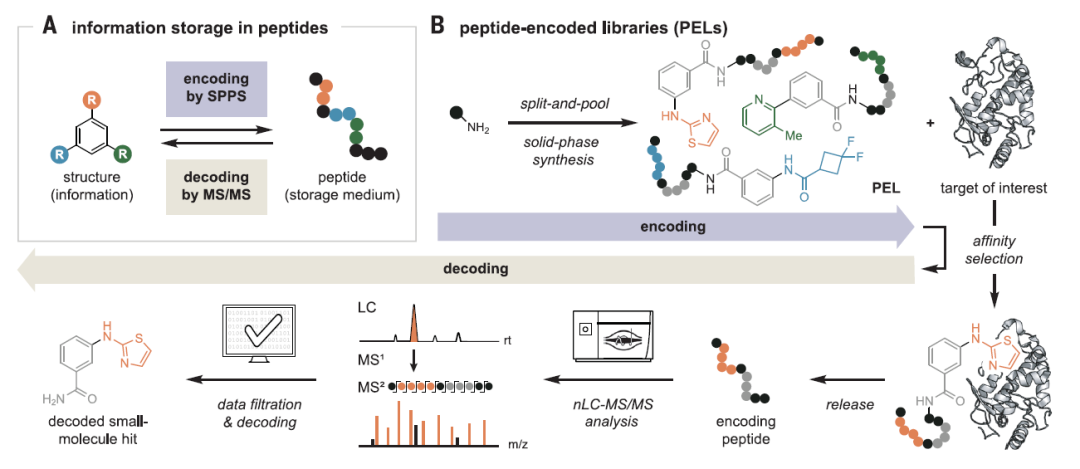
▲图1 多肽是一种适合储存编码信息的生物聚合物
利用多肽编码和解码信息
本研究设计了一组由 16 种非等压氨基酸 组成的信息单元,包括常见和特殊氨基酸,且都可以很容易的在保护其侧链的同时通过化学合成的方式引入,并通过二级质谱分析进行测序。
通过对肽链不同位点碱基和质子残基的筛选,研究发现了一种最佳的标签结构,其特征是 在 C 端和靠近 N 端有一个赖氨酸,在标签核心有一个丝氨酸,在 N 端有一个脂肪族残基(图 2A)。
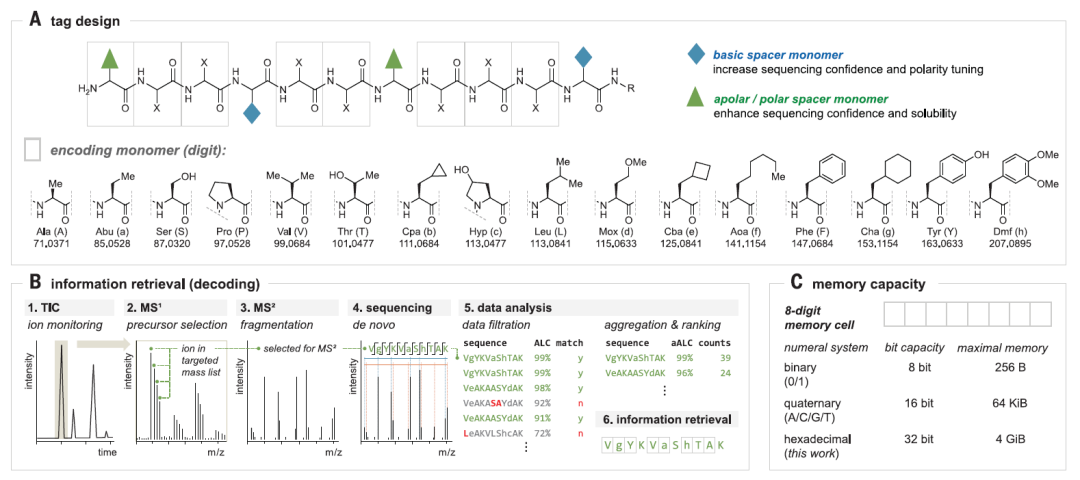
▲ 图2 肽标签编码存储模式图
这 16 种编码氨基酸的集合,可以使用 8 位(图 2A灰色框)编码字符串将数百万条信息存储在平均分子量< 1.5 kDa 的肽标签中。从理论上讲,十六进制下,8 位字符串中可以存储多达 43 亿个 代码(图 2C,168),而二进制或四进制数字系统分别只能存储 256 或 56,535 个。
与 DNA 标签相比,肽标签中编码的信息在恶劣的化学环境中也能保持稳定。在四氢呋喃 ( THF ) 溶解的乙酸钯 ( II ) ( Pd(OAc)2 ) 溶液、三氟乙酸 ( TFA ) 水溶液、氢氧化钠(NaOH)水溶液以及紫外线照射4小时等极端化学、物理条件下均能保持 95% 以上的完整性( 图 3 )
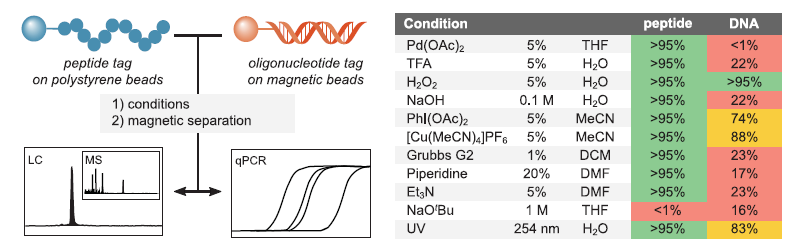
▲图3 多肽和 DNA 标签在相同合成条件下的稳定性
小分子偶联物的合成
进一步的,作者对该系统进行了优化,建立了一个 具有两个位点的分子支架,小分子通过 可被强酸裂解的 Rink 酰胺 linker 固定在聚苯乙烯珠上,一端通过 可被特定氧化条件断裂的 Seramox ( Smx ) linker 连接带有编码信息的肽链,另一端可通过三种连接方式:酰胺耦合、钯催化的 C-N 键耦合和 C-C 键耦合,进行正交合成,与另一个小分子偶联。
建立了一个可以实现 对添加了多肽标签的小分子进行多类型合成的体系,为新的化学空间的探索提供了便利。
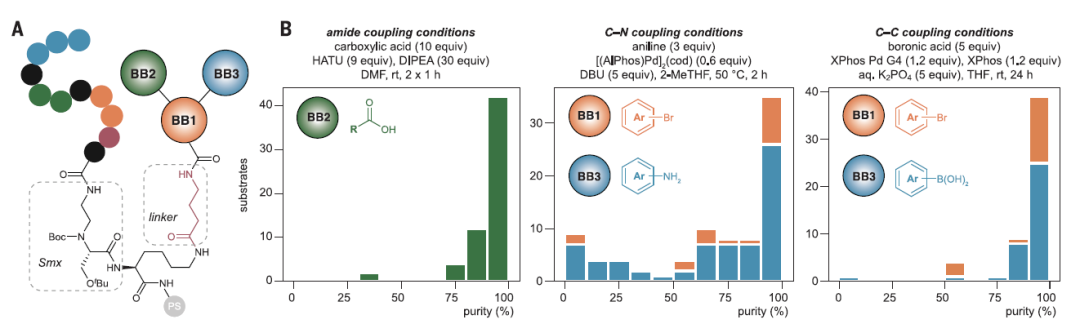
▲图4 由三种构建单元和11种编码氨基酸形成的小分子肽缀合物为更多种反应的实现提供了合适的支架
肽编码的小分子化合物库筛选
最后,作者优化出了一套 PELs 亲和筛选流程(图5 A)。
以 碳酸酐酶 IX ( CA IX ) 为例,CA IX 是一种参与肿瘤酸中毒的金属酶,是肿瘤学研究的重要靶点。
CA IX 由于能与带有锌活性位点的 磺胺类化合物 结合,是 DEL 筛选中的热门蛋白。
作者采用图 4A 所示的 PEL 设计,通过对 400 种 PEL 磺胺小分子的 孵育浓度、肽标签裂解条件 和 脱盐程序 评估,得到了最优的亲和选择条件。

▲图5 借助 PELs 发现对 CA IX 具有高亲和力的新型小分子
使用优化的亲和选择方案,作者对 41k 种 C- N 和 39k 种 C- C 连接的两种 PELs 进行了针对固定化 CA IX 的亲和力筛选,寻找 对 CA IX 具有纳摩尔亲和力的小分子(图 5A,步骤 1)。
在自动选择过程中,生物素化的 CA IX 被固定在链霉亲和素磁珠上,并用 PEL 培养。随后,反复洗涤去除非结合组分。在氧化条件下释放编码肽,进行 nLC-MS/MS 分析。将目标蛋白与无功能的链霉亲和素磁珠结合的结果作为结合特异性对照。在对多肽标签进行测序后,根据文库设计对重复数据进行过滤整合,根据编码序列在目标蛋白与对照蛋白中的数量分别进行排序(图 5A,步骤 2)。
序列置信度由对应的平均 ALC 和靶点特异性表示,并作为 苗头化合物 选择的参考(图 5A,步骤 3)。
解码肽标签所代表的相应的小分子,并给出几个 候选分子(图 5A,步骤4)。
进一步筛选类药性质,筛选出 11 个苗头分子。通过 2 天左右的时间,将其再次在固体载体上合成(图 5A,步骤 5)。
纯化一次后,通过 生物层干涉技术 ( biolayer interferometry,BLI ) 对单独合成的小分子进行验证(图 5A,步骤 6)。
所有苗头分子都与 CA IX 具有 个位数或低两位数纳摩尔范围 的亲和力(图 5B),具有成为候选分子的潜力。
此外,作者还合成了与 C-N 和 C-C 连接 PELs 相对应的无附加小分子肽库,与 CA IX 进行亲和选择,未观察到富集。表明 PELs 并不影响结合,进一步证实了该方法在苗头化合物发现中的适用性。
总结
综上,作者使用 肽编码化合物库 ( peptide-encoded libraries, PELs ) 作为信息存储系统,通过多肽固相合成和 nLC-MS/MS 测序解码,建立了一个 化学稳定性高、容量大且对蛋白-化合物亲和结合影响小 的新型化合物筛选体系。为生化数据存储、肽小分子合成和药物发现等领域都提供了一套很有应用前景的新框架。
科研助力
当下,药物高通量筛选 依旧如火如荼,TargetMol® 可以提供可以提供 超过 110 万种 分子砌块、 超过 3 万种 双官能团分子砌块、超过 1500 种 三官能团分子砌块,涵盖 硫醇砌块、伯胺砌块/仲胺砌块、磺酰卤砌块、芳香杂环砌块 等多种类别,包括多种独家分子砌块,满足大部分 PELs 合成的需求,助力您的新药研发工作。欢迎
👉
好了,今天的T仔号文献列车即将到站。希望大家科研顺利噢,我们下次再见~
参考文献:
[1] Rössler SL, Grob NM, Buchwald SL, Pentelute BL. Abiotic peptides as carriers of information for the encoding of small-molecule library synthesis. Science. 2023;379(6635):939-945. doi:10.1126/science.adf1354
06-18 TESCAN中国
解决临床创新“卡脖子”难题,丹纳赫重磅推出医院创新转化解决方案!06-18
徕卡精准空间生物学解决方案 第三弹06-18 郑晓业、童昕
618 嗨购一起“徕” | 网上商城活动来袭!06-18 徕卡显微系统
【培训活动】显微镜成像高阶培训系列(一) 共聚焦多维度成像技术解决方案06-18 徕卡显微系统
【展会】第十五届中国医师协会骨科医师年会06-18 徕卡显微系统
【直播预告】第十届电子显微学网络会议06-18 徕卡显微系统
【案例研究】双视野光片显微镜,适用于类器官及胚胎06-18 徕卡显微系统
议程确定|第四届锂离子电池热测试主题研讨会06-18
文献解读|安徽理工大学马衍坤教授团队《煤炭学报》:震动载荷多次作用下烟煤孔裂隙结构演化特征试验研究06-18 纽迈分析
中国的新质生产力正在服务全球市场!GE医疗北京基地CT交付量达3.5万台/套06-17
兰格ACHEMA 2024展会回顾:探寻精密流体传输市场新机遇06-17
宝英科技推出VOCs治理设施精细化管理实施方案,助力重点行业企业绿色升级06-17 宝英科技
赛默飞X先锋“肽”势:多肽药物研发与创新研讨会06-17
一省检验检测行业营收突破160亿元!06-17
仪器租赁 | 沃特世 液质联用,月租金52000元起06-17
不同行业实验室“以旧换新”,涉及哪些仪器设备?06-17
目标!检验机构总营收超100亿!06-16
一张“A4纸”售价高达万元,这家第三方检测公司是怎么做到的?06-15
GLMY创想仪器丨参加东北地区铸造年会06-15 国产精密仪器厂家