


文末有彩蛋 | 垃圾分类这么久,这个操作,你们造吗?
上海垃圾分类已实施两个多月,回想《上海市生活垃圾管理条例》实施仿佛就在昨天,魔都被垃圾分类逼疯,不谈论股票和房价,一门心思研究垃圾分类。垃圾分类是一个全球性难题。日本用了28年,才形成全民参与氛围,德国把垃圾分类当一项系统工程,大约40年才见效果。而如今,上海已经勇敢迈出了第一步。到2020年底,我国还将有46个重点城市要基本建成“垃圾分类”处理系统;2025年底前,全国地级以上城市要基本建成“垃圾分类”处理系统。所以在这场垃圾攻坚战中,没人能置身事外。
就在魔都忙着垃圾分类的时候,“科研猿”们也在努力搞定生活垃圾的分析检测。众所周知,通过焚烧垃圾的快捷处理,可以把垃圾转化成热能,实现垃圾的局部资源化。但垃圾焚烧带来的二噁ying污染问题引起了世界各国的普遍关注。据世界卫生组织介绍,二噁ying排放后可远距离扩散,一旦进入人体,将长久驻留,破坏人类免疫系统、改变甲状腺激素和类固醇激素以及生殖功能,甚至是影响人体发育,导致胎儿畸形。因此加强垃圾焚烧中二噁ying污染物的监控,对城市生活垃圾处理和环境保护至关重要,目前二噁ying分析方法有同位素稀释高分辨气相色谱串联质谱法。同时已有研究团队在着力推进三重四极杆气质在二噁ying等分析种中的应用。

说到色谱质谱串联法,如果您一直关着我们麦特绘谱的话,对它不会陌生。色谱质谱串联法不仅在垃圾分类及处理检测中意义重大,在代谢组学技术领域更是一种重要的检测技术平台。这里,我们来重点聊一聊检测完毕后如何进行必不可少的模型构建、评价,以及差异筛选。
模型构建
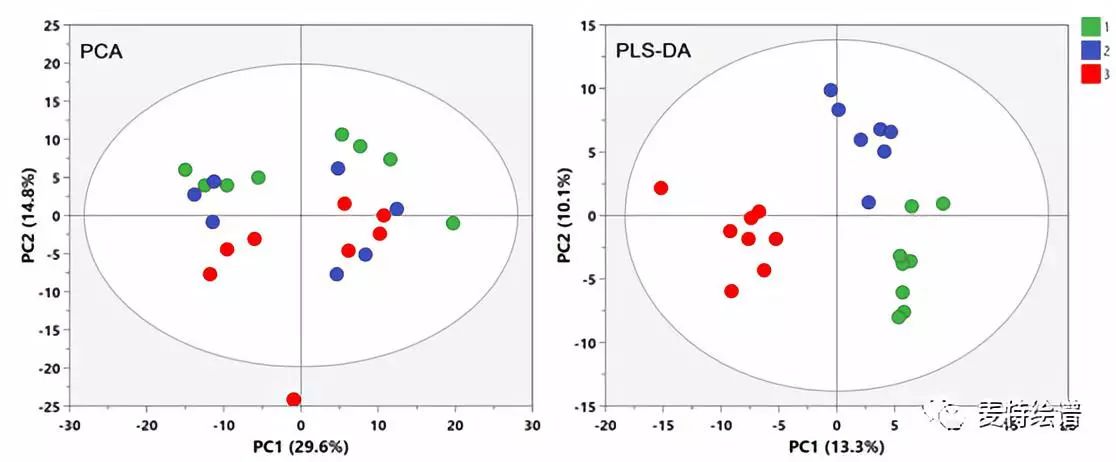
代谢组学数据分析中,最常用的多维模型包括主成分分析(principal component analysis, PCA)、偏最小二乘法判别分析(Partial least squares discriminant analysis, PLS-DA)和正交偏最小二乘法判别分析(orthogonal PLS-DA, OPLS-DA)。PCA属于无监督分类模型,可将多维数据不断降维形成几个主要成分(PC)来尽可能描述原始数据的特征。其中PC1描述了原始数据矩阵中最显著的特征,PC2描述了除PC1之外最显著的数据特征,依此类推。PCA通常被用于寻找离群点(outlier)及观察不同组别之间的自然聚类趋势。但对于离群点,不建议简单粗暴地删除,因为离群点通常是有趣且值得深究的。研究人员需要仔细地排查离群究竟是因为采样、前处理、检测等环节引入的误差还是客观的生物学差异引起的。利用PCA模型还可以观察样本间的自然聚类趋势,不同组别样本在PCA Score plot上即可分离是多维统计结果可靠性的最有力证据。
然而,不同组别样本不一定都存在明显的差异,尤其临床样本影响因素较多,如性别、年龄、BMI、地域、饮食、生活环境等。这些因素会给数据集带来很多和分组信息无关的噪音信号。此时,可以利用有监督的分类模型。有监督的意思就是事先告诉模型样本的真实分组信息再进行模型构建。PLS-DA能按照预先定义的分类(Y变量)最大化组间的差异,获得比PCA更好的分离效果。OPLS-DA综合了PLS-DA和正交信号过滤(orthogonal signal correction, OSC)技术,能够把与预先设定的和分类无关的信息最大程度从原始矩阵分离,从而将最相关的因素集中到第一个主成份(Predictive component)上,进而寻找该主成分的正交矫正轴方向,从而使组内差异弱化,组间差异最大化。PLS-DA可以用于两组以上组别的分类比较,而OPLS-DA通常用于两组间找差异。
模型评价
有监督的分类模型有一个缺点就是可能会出现过拟合(over-fitting)现象,即模型可以很好地将样本进行区分,但用来预测新的样本集时却表现很差。因此对于有监督的分类模型,我们需要验证模型的可靠性,常见的模型评价方法如下:
1. K折交互验证(K-fold cross validation)
最可靠的方式是将数据分为训练集(Training set)、验证集(Validation set)和测试集(Test set),训练集用于训练模型,验证集优化模型,测试集测试模型的预测能力。但受限于样本数量,通常采用K折交互验证。其中七折交互验证较为常用,即将数据集分为7份,每次挑选出1份作为测试样本,剩余的6份用来训练建模,整个过程将会被重复直到所有样品都被预测过。预测的数据将会和原始数据作对比得到预测残差平方和(Predicted residual sum of squares, PRESS)。为方便起见,将PRESS转变为Q2(1-PRESS/SS)。Q2越大表示模型的预测能力越好。对于生物样本,Q2≥0.4是比较理想的,Q2≥0.2往往也可以接受,只是模型比较弱。软件自动建模(Autofit)时,会根据Q2决定模型所用的主成分或Orthogonal component个数(OPLS-DA模型)。当Q2停止增长时,模型将不再增加主成分。
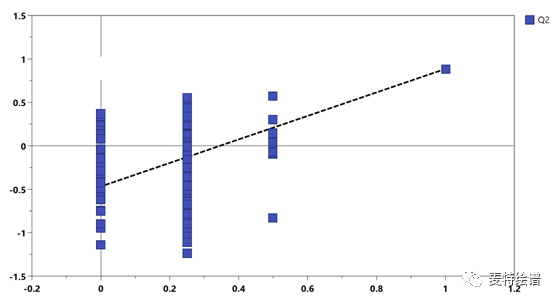
2. 置换检验(Permutation test)
仅用Q2仍不足以证明模型的可靠性,置换检验也是常用的模型评判方式,常和Q2结合使用。其原理是将每个样本的分组标记随机打乱,再来建模和预测。一个可靠模型的Q2应当显著大于将数据随机打乱后建模得到的Q2。基于置换检验结果,可以画出Permutation plot(图6)。该图展示了置换检验得到的分组变量和原始分组变量的相关性以及对应的Q2值,虚线为回归线。一个可靠的有监督模型要求回归线在Y轴上的截距小于0。
差异代谢物筛选
筛选差异代谢产物通常基于OPLS-DA模型,因为它更易于进行模型解释,所有跟分组相关的信息都集中于第一维。筛选的标准通常是基于以下两个指标:
Corr.Coeffs./p(corr) (Correlation Coefficient),是样本得分值t和变量X间的相关系数-Corr(t, X),代表了变量的可靠度。该值没有固定阈值,通常设定对应的P值 < 0.05。
VIP (Variable importance in the projection),为变量对模型的重要性,描述了每一个变量对模型的总体贡献,通常设定阈值为VIP >1。
除此之外,基于单维检验的P值和变化倍数(Fold change)所作的火山图(Volcano plot)也是常用的筛选方法。
差异代谢物组合的判断是需要技巧的,并不是说数学上统计出来p<0.05的top的组合就可以了,实际上组合的优化一定是统计模型和代谢通路两者兼顾再优化的结果,是“代谢组学驱动下的分子生物学机制研究”。
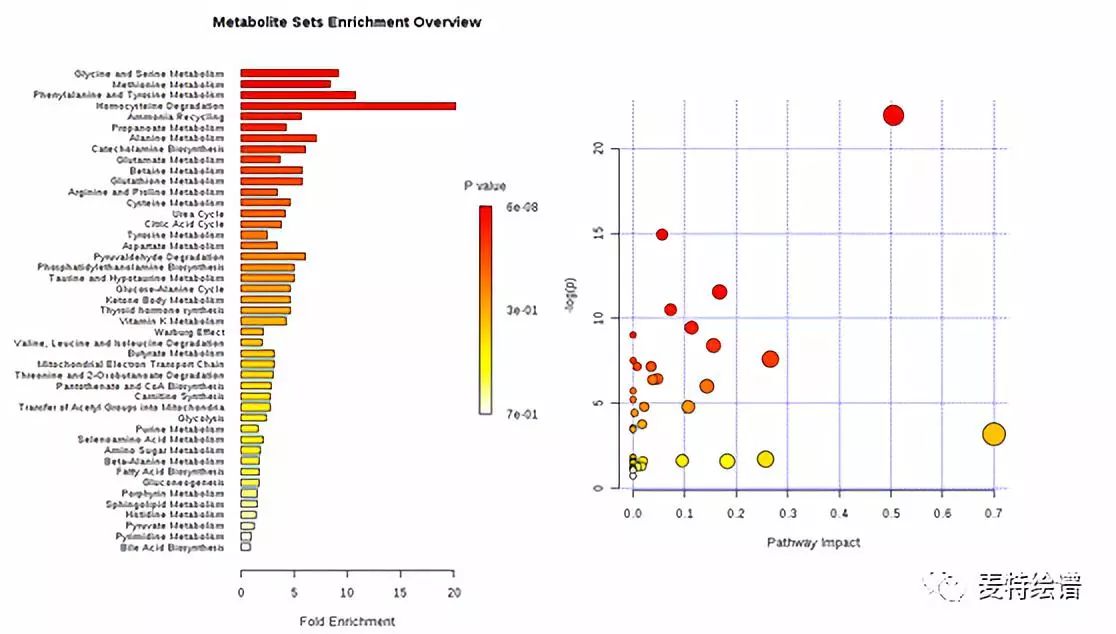
通路分析
通过上述方法筛选到差异代谢物后,还需要挖掘和这些代谢物相关的代谢通路。采用MetaboAnalyst(http://www.metaboanalyst.ca/)进行代谢通路分析(Metabolic pathway analysis),可分为富集分析(Enrichment analysis)和通路分析(pathway analysis)。通路分析中包括通路拓扑分析(topology analysis),会输出通路在整体网络中的重要性(impact)。
代谢组学的数据处理远不止于此,若您意犹未尽,欢迎在下方留言,一起交流讨论!
欢迎关注麦特绘谱微信公众号,解锁更多精彩「代谢组学」相关资讯!
参考文献
Westerhuis, J.A., et al., Assessment of PLSDA cross validation. Metabolomics, 2008. 4(1):81-89.
彩蛋时间到了~
重要的事情说三遍!
麦特绘谱新品发布了!!!
新品发布了!!!
发布了!!!
麦特绘谱重磅推出代谢组学臻品--“Q300代谢芯片”检测方案,基于LC-MS/MS高通量绝对定量检测300+种代谢物;实现在同一微量滴定板上对生物样品中跨量级的代谢物类群进行绝对定量检测,囊括了碳水化合物类、有机酸类、氨基酸类、脂肪酸类、胆汁酸类、吲哚类、苯环型化合物等代谢物类群;适用于血清、血浆、组织、粪便、尿液、细胞、细胞培养液、唾液等各种生物样本。既能满足生物样本代谢物多种类检测,又能对代谢物进行绝对定量分析!只有想不到,没有做不到!快快联系我们下单吧!
微信公众号:麦特绘谱
Tel:400-867-2686
Email : marketing@metaboprofile.com
Web: www.metaboprofile.com

| 标签: | 垃圾分类 色谱质谱串联法 麦特绘谱 |